rCore 操作系统中的上下文切换
程序的函数调用和返回是在栈上增加与减少栈帧,而 trap 是换栈,自己以前一直概念混淆了。
考虑函数
1
2
3
4
5
6
7
8
9
10
11
12.global sum_then_double
sum_then_double:
addi sp, sp, -16
sd ra, 0(sp)
call sum_to
li t0, 2
mul a0, a0, t0
ld ra, 0(sp)
addi sp, sp, 16
ret
如果仅仅写成
1 | .global sum_then_double |
会有什么问题?
考虑被去掉的代码的作用,addi sp, sp, -16 将程序栈顶下移 16 个地址,即为函数 sum_to 分配了大小为 16 的栈帧,然后 sd ra, 0(sp) 将 ra 寄存器的值保存在了栈顶地址处
函数逻辑执行完后,ld ra, 0(sp) 恢复 ra 寄存器(需要恢复是因为伪指令 call 会将 ra 的值修改为 pc + 4 ),然后 addi sp, sp, 16 释放了当前函数的栈帧,最后伪指令 ret 将 pc 值修改为 ra 中的值,即完成了函数返回跳转。
据此解答上面的问题,如果函数中去掉了保存 ra 的操作,则执行计算之后执行 ret 指令时,ra 的值仍然为 li t0, 2 这一指令所在的地址,因此程序成为了死循环。
- 关于 os 的栈的初始化
1 | .section .bss.stack |
按照 linker.ld ,linker 从低地址向高地址布局到 .bss 段,boot_stack 为低地址而 boot_stack_top 为高地址,在 .bss 段开辟一个 4096 * 16 大小的数组给内核作为栈来方便内核内的函数调用,这些调用的栈帧变化是 rust 编译器帮我们实现的。
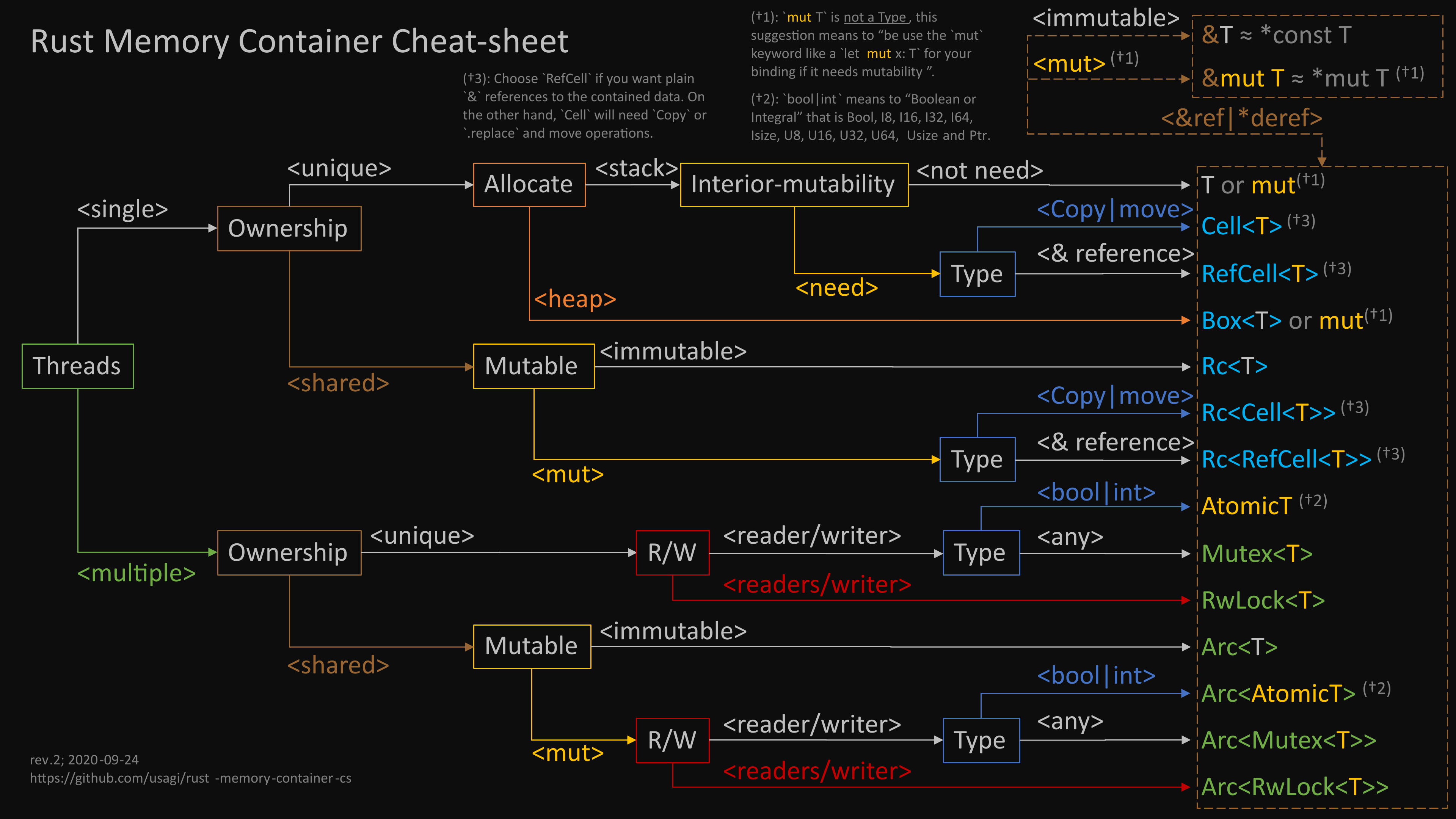
- 一张很大程度上帮助我理解 os 的图

- Trap 是如何实现的
首先 qemu 加电,执行 rustsbi 的一系列初始化任务,然后按照约定跳转到 rust_main 将控制器交给 rust ,rust_main 中执行了 trap::init,其代码如下:
1 | pub fn init() { |
即将寄存器 stvec 的值设为了 __alltraps 的地址:
1 | __alltraps: |
__alltraps 处向后的指令即为进行上下文保存的操作,随后 call trap_handler 将控制权正式移交给内核。
因此整体流程即为:用户态程序发出 ecall 指令,一些 CSR (如 scause, stval 等)的值将被相应地设置,PC 值将被设置为 stvec 中保存的值(PC 原来的值保存在 sepc ,方便之后 sret 返回),也就是 CPU 开始执行 __alltraps 处的指令,从此处开始向后执行上下文的保存(这时其实 PC 已经指向内核中了,应该可以说是已经进入了内核态?),完成上下文保存后调用内核的 trap_handler 函数,开始内核代码的执行。
- 关于 ch2 中 app 是如何开始运行的
主要是理解全局 APP_MANAGER 的初始化和 load_app。
1 | lazy_static! { |
首先找到 _num_app ,让 num_app_ptr 指向 _num_app 的地址,变量 num_app 保存 _num_app 的值,即 7 ,app_start 是一个数组,其中保存了所有 app 程序的起始地址(从 link_app.S 可以知道所有 app 程序都已经放在了操作系统的 .data 段这片内存上,即还是编译成了一个整体),最后追加了一个最后一个 app 的结束地址(前面的 app 不需要结束地址,因为下一个 app 的开始地址就是上一个的结束地址)。
接下来是 load_app
1 | unsafe fn load_app(&self, app_id: usize) { |
首先把 icache 和 0x80400000 开始的一段内存清零,然后把下一个 app 程序从内核的数据区拷贝到 0x80400000 开始的这段内存中。
再接下来是 run_next_app
1 | pub fn run_next_app() -> ! { |
这里感觉理解得不一定对,先放一个 TODO
此处的 KERNEL_STACK 和 USER_STACK 两个静态全局变量应该都是放在内核的 ro 数据段的,也就是把用户栈放在了内核的数据段?这一段似乎是向 KERNEL_STACK 压入了一个初始化的 trap 上下文,然后也许是通过 a0 把此时的内核栈顶,也就是刚压入的上下文的最低地址,赋给了 sp ,使得第一次开始执行 app 的操作也能复用 __restore 的代码。那这里有了 一开始的 boot_stack 干嘛去了呢?
指导书的回复:
@bswaterb 64KiB的空间是启动栈,仅在内核初始化自身,也就是调用rust_main函数直到task::run_first_task之前由内核使用。在此之后应用使用UserStack而内核使用KernelStack,启动栈不再被使用。
- ch2 的思考:sscratch 是何时被设置为内核栈顶的?
可以反过来思考,进入第一个应用程序执行的前一步,是内核第一次执行 __restore ,在 __restore 中有这样的操作:
1 | mv sp, a0 |
a0 中保存的内容是压入初始化 trap 上下文的内核栈的栈顶,之后传递给了 sp ,然后将 sp 往上偏移 2*8 字节处的内容写入了 sscratch ,那这个偏移处的内容是什么呢?查看 TrapContext 的定义:
1 | pub struct TrapContext { |
通过这个定义可以知道写入 sscratch 的就是 x[2] 。那 x[2] 又是啥?
1 | pub fn set_sp(&mut self, sp: usize) { |
原来 x[2] 就是用户栈的栈顶。那么这个思考题就解决了,在内核启动后第一次进入用户态执行应用时,也就是 trap.S 的 __restore 函数中
1 | __restore: |
- 当一个 app 执行结束后是如何开始执行下一个的
每个应用程序的 .bin 文件中都有一份 lib 中的代码,他们的入口点都是 _start ,在 _start 完成初始化工作之后调用对应 app 的 main ,将 main 的返回值传给系统调用 exit ,从 exit 处发出 ecall 陷入内核态,在内核态中,sys_exit 再次调用了 run_next_app ,于是下一个 app 程序被拷贝到了 0x80400000,实现了批处理。
- 串一下今天读的 ch2 源码,如果完整顺下来今天就休息了
首先编译应用程序,之后编译内核,编译内核的过程中把应用程序也都集成在了内核里,放在了内核的数据区。内核启动的第一条指令是把 sp 放在一个预留的 4096 * 16 大小的 boot_stack 里作为内核启动栈。内核启动后要执行一些初始化,主要是初始化 trap 控制,即设置好 stvec ,使得 ecall 发生后能正确跳转到处理陷入的代码,也就是 __alltraps,另外,在内核的 .rodata 段初始化两块内存,分别作为用户栈和内核栈,启动时的启动栈之后就不再使用。然后就初始化一个全局的 app manager,完成初始化后,就通过 load_app 将第一个应用程序拷贝到 0x80400000,准备切换到用户态。
首次切换到用户态时为了能够复用 __restore ,我们“假装”当前所在的内核态是之前的某个用户态切换过来的,因此我们在内核栈里压入一个经过设计假的 trap 上下文,__restore 根据这个我们设计的上下文进行寄存器的恢复,比如把 sepc 设置为 0x80400000,把 sp 设置为用户栈的栈顶(USER_STACK.get_sp()),然后 sret 让 pc 跳转到 sepc 指向的地址,也就是 0x80400000,开始执行第一个应用。
对于一个应用,其入口点是 lib.rs 中的 _start ,也就是 0x80400000 处的程序就是这个用户库里的 _start ,_start 进行了一定的初始化工作,然后就调用了对应的 app 的 main 函数。main 函数返回之后,_start 中把 main 的返回值作为参数交给了系统调用 sys_exit ,而 sys_exit 做的事情就是 run_next_app ,于是下一个应用像上面一样被调用。
看起来似乎每次 trap 进入内核态的时候,内核栈中会保存下一个 34*8 大小的上下文,而在内核态中,又会向内核栈压入一个我们设计好的上下文,而返回时 __restore 只会释放这个我们设计的上下文,那么似乎是运行应用时,每个应用会让这个批处理系统的内核栈里会产生 34 * 8 大小的不被清理的垃圾?但是 GDB 发现每次到 0x80400000 时,sscratch 保存的地址并没有变低,不知道是我忽略哪里,留做 todo 好了。
- ch3 的整体逻辑是怎样的?
首先 qemu 加电,内核启动,到 rust_main 接管控制权为止的部分都和之前一样。在 rust_main 中,ch3 相比 ch2 多了一步 heap_alloc ,但这里似乎不是本章任务切换的重点,暂且不管。之后 trap::init 的行为也是一样的,把 stvec 内的地址设置为 __alltraps 。
然后是 ch3 的 load_apps ,虽然不同于 ch2 的方式,但是意思不难理解,是让内核启动时将所有的 app 都加载到内存上的不同区域而已,否则在之后进行任务切换时,还需要当场向内存上拷贝应用程序。
之后的 trap::enable_timer_interrupt 启动 S 态的时钟中断,再之后的 timer::set_next_trigger 确保了在 CLOCK_FREQ / TICKS_PER_SEC 这个时间之后会发生一次陷入,好让内核切换应用。最后通过 task::run_first_task 开始执行应用程序。
接下来就是探索 task::run_first_task 中具体发生了什么。可以发现它只是调用了一个全局任务管理器 TASK_MANAGER 的方法。我们查看 TASK_MANAGER 的定义,发现它里面包括的内容有:
- 应用程序的个数
- 所有应用程序的 TCB 数组
- 当前正在被执行的应用的 id(TCB 数组中的索引)
进一步查看 TCB,里面包含了对应任务的状态(如结束、挂起、执行中等)以及该任务的上下文。
这个上下文的意思就是:过一会这个任务可能会执行一半就被时钟打断进入 trap 控制流进入内核,内核会把切换其他任务上来执行,那你这个被打断的任务当前使用的寄存器就需要被保存下来,特别是 sp 和 ra,这样之后再次轮到这个任务执行的时候,才能正常恢复。而这些内容保存的位置,就在这个任务对应的 TCB 的 pub task_cx: TaskContext 里。
那么话说回来,内核调用了任务管理器的 run_first_task 方法,这个方法做的事情就是把队列里的第一个任务拿出来,通过 __switch 开始第一个任务的执行。
这里又有很多可以说道的问题,__switch 怎么就能开始执行程序了?我们需要考察 __switch 的内部:
1 | __switch: |
__switch 接收两个任务上下文地址 current 和 next,它把当前的各个寄存器里的内容保存到 current 中,在把 next 里的数据读到各个寄存器中来。
那么任务管理器第一次调用 __switch 时的参数是什么呢?首先当前没在执行任何任务,所以 current 就用了一个 TaskContext::zero_init 出来的没用的上下文,而 next 关系到我们接下来怎么跳转到第一个应用程序,所以不能瞎填,需要构造。
我们可以停下来自己想一下这个上下文应该怎样构造。首先各个通用寄存器应该简单为 0 就可以了,因为这个应用还没开始执行,最重要的是 ra 的值如何填写。
__switch 之后,应该发生的事情和上一章差不多,应该要向内核栈压入一个构造好的假的上下文,利用这个上下文调用 __restore ,再让 __restore 通过 sret 开始执行用户程序。
查看任务管理器的初始化,我们就会发现的确是上面说的道理:
1 | for (i, t) in tasks.iter_mut().enumerate().take(num_app) { |
__switch 直接返回到了 __restore 处,并且返回到这里时,我们把 a0 设置好为我们构造好的 trap 上下文。